コレクション登録
FileBlogトーク用のシステム設定(http(s)://xxx/filetalk)で各種設定を行います。
コレクションは任意の設定です。
コレクションには2つの用途があります。
AIチャットでの質問時に表示させるヒントメニューの構築
ベクトル検索できるようにするためのベクトルインデックスデータ構築
コレクションの指定条件の対象ファイルについては、ベクトル検索用のインデックスデータが作成されます。
AIチャットの使用方法が、ベクトル検索を要しないLLMを呼び出すだけの会話(質問や要求)の実行のみであれば、コレクションの登録は不要です。
ベクトル化に向いている用途
AIチャットの検索に用いるヒントメニューを作成した場合、ヒントファイルをベクトル化しておくとヒント提示の精度(質問とヒントとの適合性)が上がる傾向にあります。
特定の文書種類を目的に検索を実行する場合は、該当するフォルダ内のファイルをベクトル化しておくと、AIの回答精度が上がる傾向にあります。(以下は特定文書種類の例)
技術資料が集められたフォルダ
過去トラブルの資料が集められたフォルダ
各種規定が集められたフォルダ
手順書やマニュアルが集められたフォルダ
大量文書を対象としたベクトル化はおすすめしません。トップレベルの階層などファイル数が数十万件を超えるようなフォルダのベクトル化はコストが大きくなります。
ベクトルインデックス構築のために長時間を要します。
ベクトルインデックス構築はAIを利用するため、出力・入力のトークン数が増加します。
コレクション定義の登録
システム設定で[コレクション]を選択します。
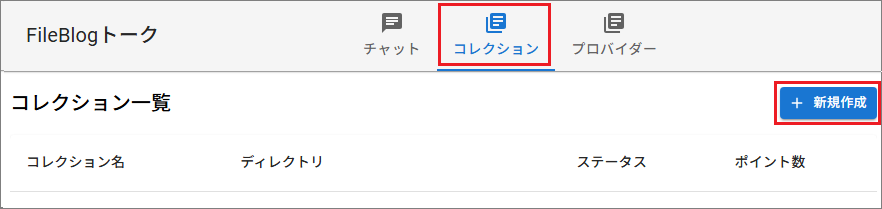
画面右上の[新規作成]を選択してコレクションの定義を登録します。
各項目を次のように設定します(最小構成の例)。
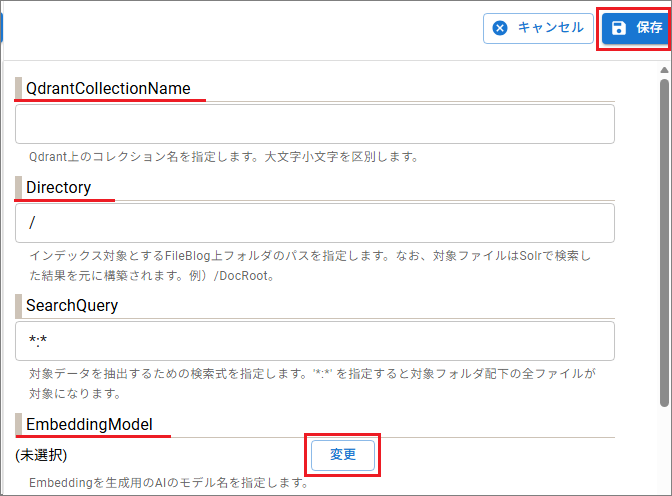
[QdrantCollectionName]:名称を登録します。半角英数字が使用でき大小文字は区別されます。チャット設定で参照する[ヒント生成元コレクション]のキーになります。
[Directory]:ベクトルインデックス登録対象となるFileBlogのフォルダパスを設定します。広すぎない範囲のフォルダを指定してください。ベクトルインデックス登録時にプロバイダーの従量課金対象となる可能性があります。
[EmbeddingModel]:[変更]を選択して、ベクトルインデックス構築に用いるプロバイダー/モデルを指定します。
設定を保存します(サービス再起動は不要です)
コレクション設定項目
設定項目 |
説 明 |
|---|---|
QdrantCollectionName |
コレクションの名前(識別子)です。 |
Directory |
指定フォルダの配下にあるファイルがベクトルインデックスデータの構築対象になります。 |
SearchQuery |
対象ファイルを抽出するための検索式です。標準既定の |
EmbeddingModel |
プロバイダーとLLMモデルを選択します。LLMがデータのベクトル化を行います。 |
ChunkSize |
ベクトル化のために分割するトークン数の単位です。 値が大きいほどノイズが増えて精度が低下する傾向です。 |
ChunkOverlap |
分割時に前後で重複させるトークン数です。文脈が保持され検索漏れを防いだり回答品質の向上に役立ちます。値が大きいほどチャンク数が増えて応答時間、利用コスト、メモリ使用量が増える傾向です。 |
インデックスデータの構築
登録したコレクションのベクトルインデックスデータを構築します。
[管理ツール > インデックス構築状況 > コレクション]を開きます。
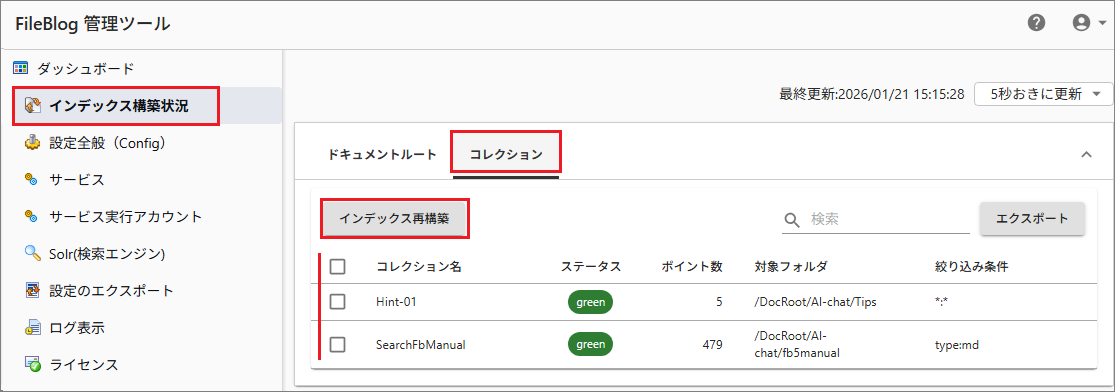
コレクションを選択して[インデックス再構築]を実行します。
タスク欄にタスクが表示されインデックス構築の進捗を確認できます。
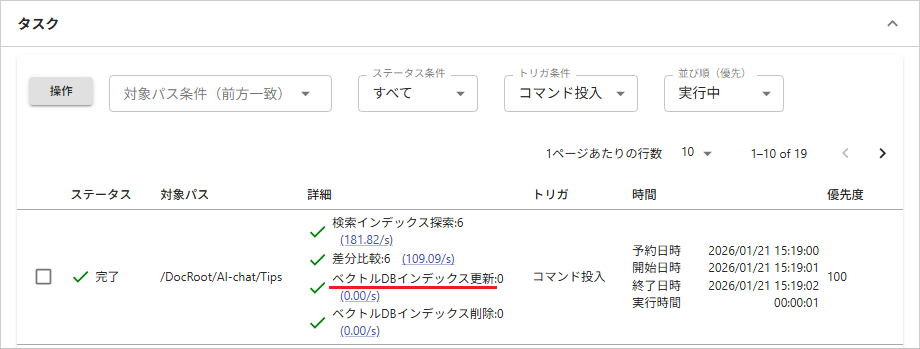
タスクが完了したら[システム設定 > コレクション > 一覧からコレクションを選択 > 検索]を開き、キーワード結果が返れば正常です。
インデックスデータの定期更新
ベクトルインデックスデータは、ファイル更新を検知して実行される即時更新には対応していません。インデックス再構築のタスクを定義して定期実行することが必要です。
[管理ツール > 設定全般 > クイックアクセス > タスクスケジュール > TaskScheduler]を選択します。
タスクを新規作成(追加)して[アクション > 追加 > 任意コマンド > ベクトルインデックス再構築]を指定します。
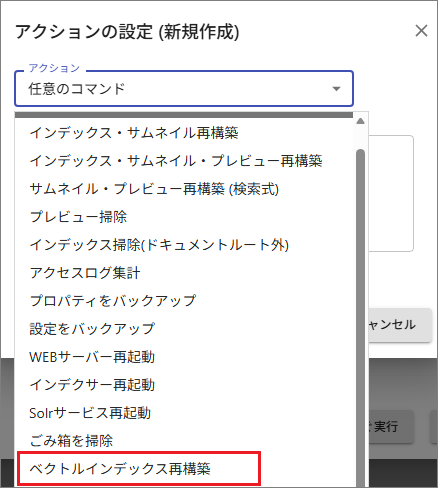
定期実行の[スケジュール]を指定します。
設定を保存します。(サービス再起動は不要です)
コレクションの公開
会話形式ではなく、キーワードに自然文を用いて検索(ベクトル検索)できるフォームを公開できます。
ポータル機能を使ってベクトル検索の画面を表示させます。
コレクション一覧にあるコレクション設定を選択して開きます。
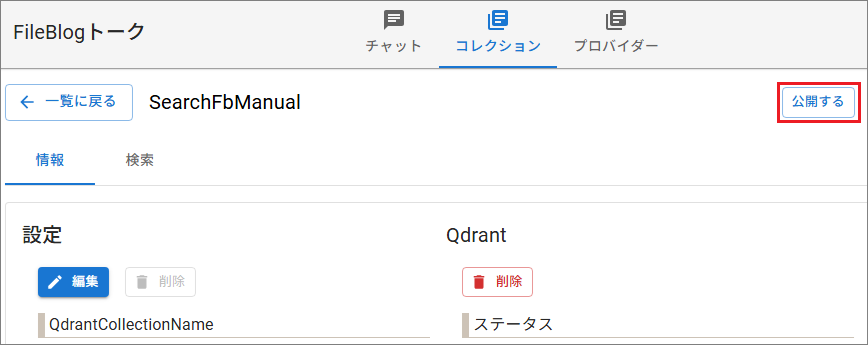
[公開する]を選択します。
[FileBlogポータルに埋め込む]を選択して表示された埋め込みコードをコピーします。
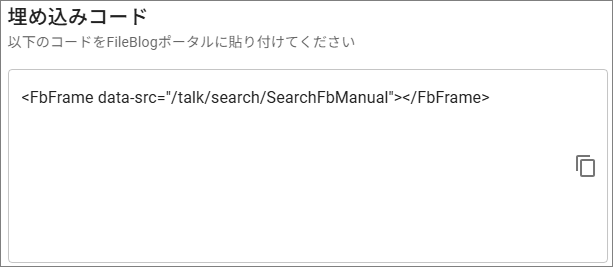
ベクトル検索画面を設置するフォルダを開き、[ファイル操作 > 新規作成 > メモ(html)]を実行します。
編集画面にコピーしたコードを貼り付けます 。
[保存する]を選択して、ファイル名を
index.thtmlにして保存します。[×]で編集画面を閉じてから画面を更新します。
ベクトル検索のフォームが表示されるので、キーワードを入力して検索結果が返れば正常です。