OCR(光学文字認識)機能
テキスト情報を保持しない画像系ファイルについてもOCR機能で文字認識した情報をテキスト化して検索インデックスに登録します。
たとえばスキャンして作成されたPDFやTIFのファイルを全文検索対象にできます。
また、OCR機能を用いてインデックス構築を実行するとコンバーター動作のメモリ使用量や所要時間が大きくなります。あわせてコンバーターの処理時間も参照してください。
OCR機能の性能について(前提)
OCR機能による文字認識の成功率は100%ではなく文字認識の正確性も完璧ではありません。
高い精度を保証するものではなく期待する結果を得られないこともあります。
OCR対象のファイル形式
PDF・TIF(TIFF)・JPG・PNG・BMPのファイル形式に対応します。
OCR機能の有効化
OCR機能を有効化すると対象ファイルを読み取って文字認識できるようになります。
[管理ツール > 設定全般 > ocr]で検索します。
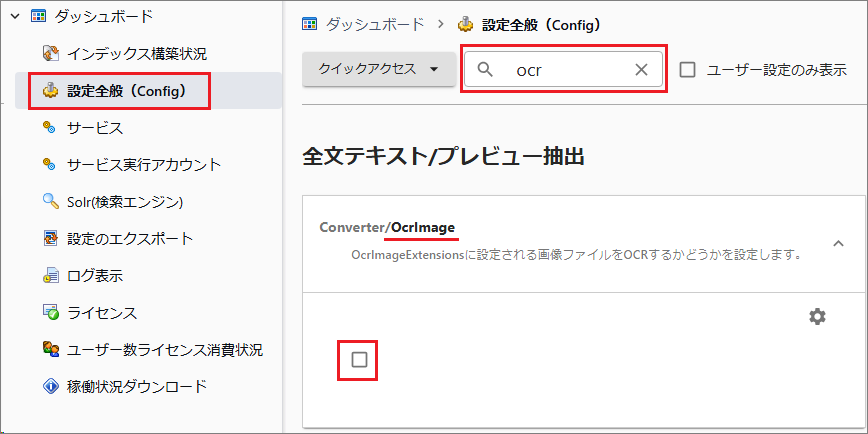
[Converter/OcrImage]を選択してチェックを入れます。
[保存する]を選択してサービスを再起動します。
PDFをOCR対象にする
[Converter/OcrPdf]を選択してチェックを入れます。

設定の変更があれば[保存する]を選択してサービスを再起動します。
OCR対象の追加
標準既定ではTIF(TIFF)が対象に指定されています。JPG・PNG・BMPも指定することができます。
[Converter/OcrImageExtensions]を選択します。

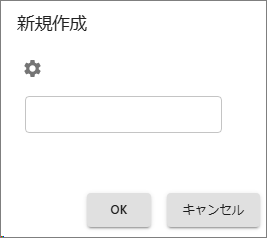
[追加]を選択して
jpg・png・bmpのいずれかまたは全部を登録します。tif・tiffを対象にしない場合は既存設定を削除します。
[保存する]を選択してサービスを再起動します。
インデックス再構築を実行します。
運用途中に対象拡張子を追加した場合
拡張子の追加登録を行ってインデックス再構築を実行しても検索インデックスに登録されない場合があります。
JPGファイルについてはインデックス初期構築が完了していると、既にEXIF情報がインデックス登録されている場合があります。
そのようなファイルについては更新日時に変更がないとOCRによるインデックス登録がスキップされます。
抽出済みテキスト情報を削除してからインデックス構築することでOCRによる認識されたテキスト情報が検索インデックスに登録されます。