抽出プログラムの動作制限
テキスト抽出およびプレビュー作成に使用する抽出プログラムは、使用できるメモリ容量および実行処理の動作時間に制限があります。
大容量ファイルや大きな用紙(A1等)から生成したデータに対する処理、OCR実行の処理では、抽出プログラムの動作制限により該当ファイルについては処理が途中停止して完了できないことがあります。
処理が完了できないと該当ファイルのテキスト抽出やプレビュー作成はできず、次回より処理がスキップ されるようになります。
メモリ使用容量
次のような症状が発生したら抽出プログラムのメモリ使用上限を超過しています。
プレビュー作成に失敗して次のエラーが出力される。
The external process exceeded the working set size limit. (maxWorkingSet=1024MB) (programpath=Teppi.FileBlog.Converter.exe)
OCR機能を有効化した状態でインデックス再構築後に対象ファイルについてテキスト抽出されない、または白紙のbodyu.txtが出力される。
メモリ使用上限を変更する
[管理ツール > 設定全般 > クイックアクセス > メモリ上限]を選択します。
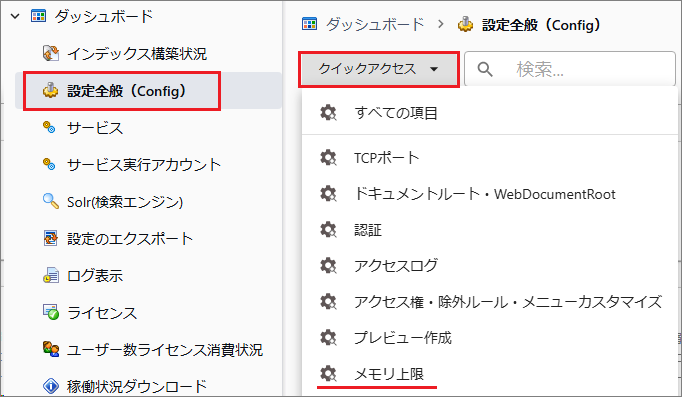
[Converter/MaxWorkingSetSize]を選択します。
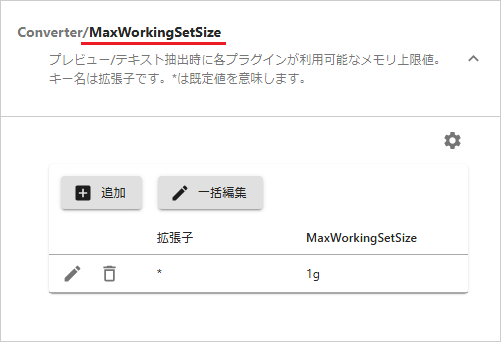
標準既定のペンシル-マークを選択して編集ダイアログで上限値(value)を編集します。ファイル種類別に指定する場合は[追加]を選択して拡張子(Key)を指定します。
[保存する]を選択してサービスを再起動します。
変更には次の点を注意してください。
マシンに実装されているメモリ容量を超える値を登録しないでください。
メモリ容量の少ないマシンでは値を大きくすると、処理中にマシンやシステムが不安定になる可能性があります。
処理結果を確認しながら段階的に上げていくことをおすすめします。
テキスト抽出のタイムアウト
次のような症状が発生したら抽出プログラムの処理時間が超過(タイムアウト)しています。
ファイルのプロパティに次のように表示されるとタイムアウトの可能性があります。

ログ(idxsvr.log)またはプレビュー保存フォルダに次のように出力されているとタイムアウトしています。プレビュー保存フォルダの該当ファイルに紐づくフォルダに
bodyerror.txtファイルが出力されます。lv:WARN msg:failed to filter text. (message=The external process exceeded the timeout limit. (timeout=00:01:00)
テキスト抽出の制限時間を変更する
[管理ツール > 設定全般 > timeout]で検索します。
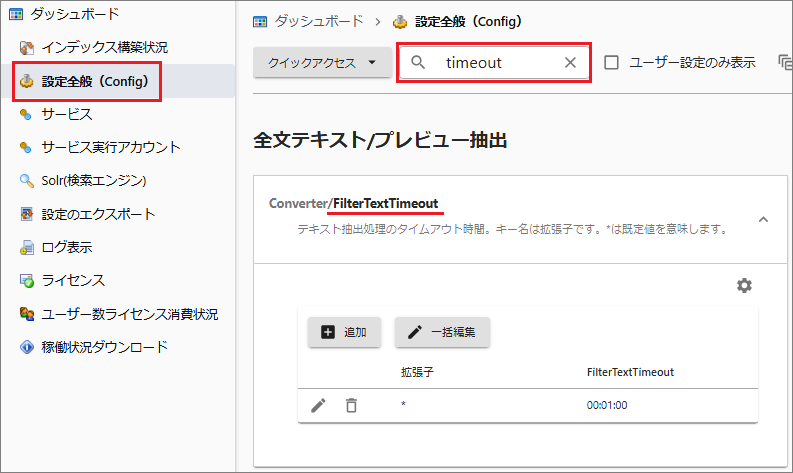
[Converter/FilterTextTimeout]を選択します。
標準既定のペンシル-マークを選択して編集ダイアログで上限値(value)を編集します。ファイル種類別に指定する場合は[追加]を選択して拡張子(Key)を指定します。
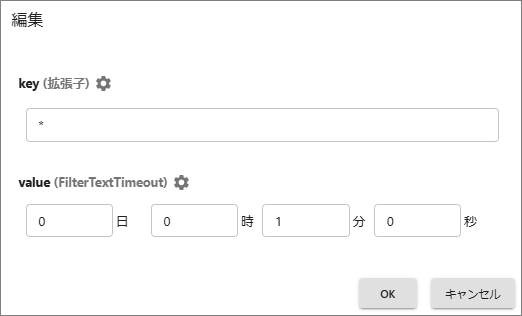
設定を保存してサービスを再起動します。
プレビュー作成のタイムアウト
プレビュー作成に失敗して次のようなエラーが出力されたら処理時間が超過(タイムアウト)しています。
プレビュー抽出処理にタイムアウトしました。
---
The external process exceeded the timeout limit. (timeout=00:01:00)
プレビュー作成の制限時間を変更する
[管理ツール > 設定全般 > timeout]で検索します。
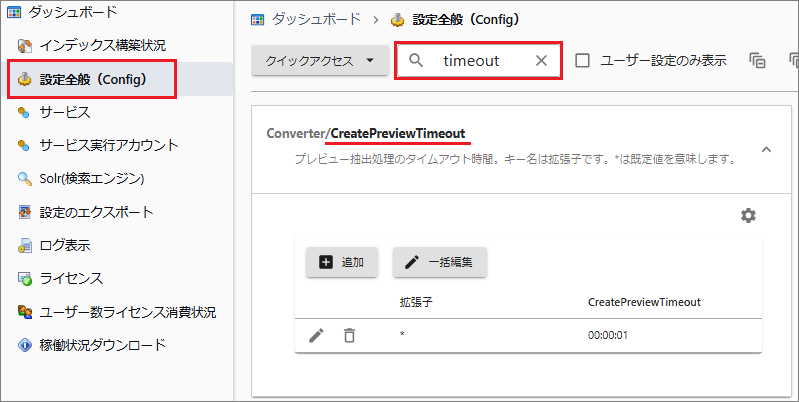
[Converter/CreatePreviewTimeout]を選択します。
標準既定のペンシル-マークを選択して編集ダイアログで上限値(value)を編集します。ファイル種類別に指定する場合は[追加]を選択して拡張子(Key)を指定します。
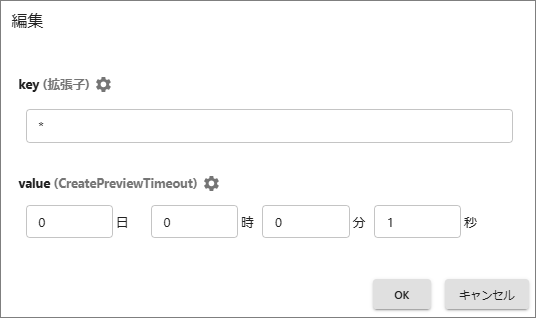
設定を保存してサービスを再起動します。
設定変更後のインデックス再構築
テキスト抽出・プレビュー作成に失敗したファイルは次回の処理がスキップされるようになります。
スキップされないようにするには、インデックス再構築の実行前にプレビュー保存フォルダに作成されたファイルの削除が必要です。
テキスト抽出の失敗時:
bodyu.txtまたはbodyerror.txtを削除します。プレビュー作成失敗時:
error.txtを削除します。
コマンドラインツールでフォルダやファイル種類を指定して一括削除することもできます。